The tool will generate text of images and documents without embedded text. Several features use this generated text such as:
•Keyword searching
•Productions (exporting a separate .txt file for each document)
•Enabling AI Search
To access the functions:
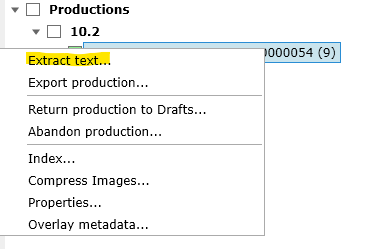
•Right-click on the filter tree and select "Extract Text..."
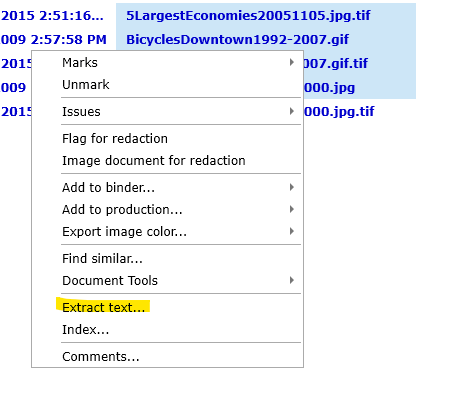
•Right-click one or more selected documents and select "Extract text..."
In the dialog choose the option needed for the data set:
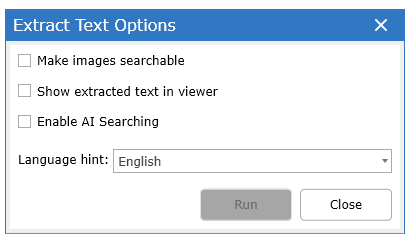
•Make production images searchable - create text searchable PDFs for export either in a production or as individual documents (see Exporting Documents)
•Extract and save text - for productions requiring a text file for each document
•Enable AI Search - turn this on to generate AI Search indexes
•Overwrite exiting text - for use when existing text should be replaced (all other options will skip documents for which text has already been extracted)
•Attempt forced OCR of PDFs - certain PDFs are delivered with an overlaid text file (usually a form or a produced PDF with a Bates number overlaid) in which only the text overlay is indexed. This option forces the tool to use Optical Character Resolution of the PDF image and not extract the overlaid text.
When data sets involve additional languages the OCR engine can be optimized to recognize those languages.
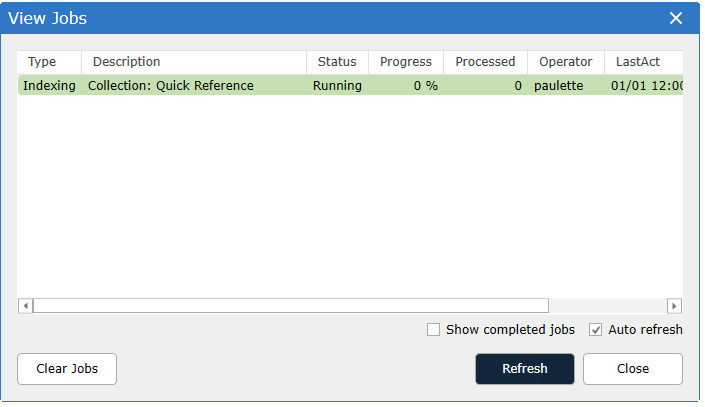
To monitor the progress go to the Process tab and select the View Jobs interface.
After the tool completes extracting text where available from the documents, any document where text was not extracted will be OCR'ed and the results from that OCR will be added to the Index.